6 Critical Facts About GLiGuard: The Tiny Safety Model That Outperforms Giants
As AI agents and LLM-powered applications move from prototypes to production, one silent bottleneck is throttling performance: safety moderation. Every user prompt and every model response must be screened, and that means your guardrail model runs on every single interaction. The cost and latency add up quickly. Enter GLiGuard, a 300 million parameter open-source model from Fastino Labs that achieves accuracy matching or exceeding models 23 to 90 times its size while running up to 16 times faster. Here are six things you need to know about this compact powerhouse.
- The Hidden Cost of Safety Moderation
- Why Decoder Models Are a Poor Fit for Safety Tasks
- GLiGuard's Encoder-Based Breakthrough
- Benchmark Dominance Against Massive Models
- Speed and Efficiency That Redefine the Standard
- What This Means for Production AI Systems
1. The Hidden Cost of Safety Moderation
When you deploy an LLM system in production, the safety layer is not a one-time check—it runs on every user prompt and every model response. That means for a typical conversation, the guardrail model is invoked multiple times. With current generation models like LlamaGuard4 (12B parameters), WildGuard (7B), ShieldGemma (27B), and NemoGuard (8B), that can lead to massive operational expenses. Each inference consumes significant compute and memory, and latency compounds as the conversation deepens. Fastino Labs recognized that safety moderation had become one of the most operationally expensive parts of the stack, and they set out to solve it with a dramatically smaller alternative.
2. Why Decoder Models Are a Poor Fit for Safety Tasks
Most existing guardrail models are built on decoder-only transformer architectures that generate safety verdicts autoregressively—one token at a time, just like a chatbot generating a reply. This design was chosen for flexibility: decoder models can interpret natural language task descriptions and adapt to new policies without retraining. However, autoregressive generation is inherently sequential, making it slow and computationally heavy. The problem worsens when multiple safety dimensions need to be evaluated—harm type, prompt injection, response safety—because each assessment is done one after another. So the very architecture that enables adaptability makes decoder models the wrong tool for what is essentially a classification problem.
3. GLiGuard's Encoder-Based Breakthrough
GLiGuard takes a fundamentally different approach by reframing safety moderation as a text classification problem. Instead of generating output token by token, it uses an encoder architecture that processes the entire input at once and outputs a single classification label for a fixed set of categories. This makes it blazingly fast—latency is constant regardless of the number of safety dimensions being evaluated, because all dimensions are assessed in a single pass. The model is just 300 million parameters, but it packs a punch by focusing computational power where it matters: accurate classification without the overhead of generative decoding.
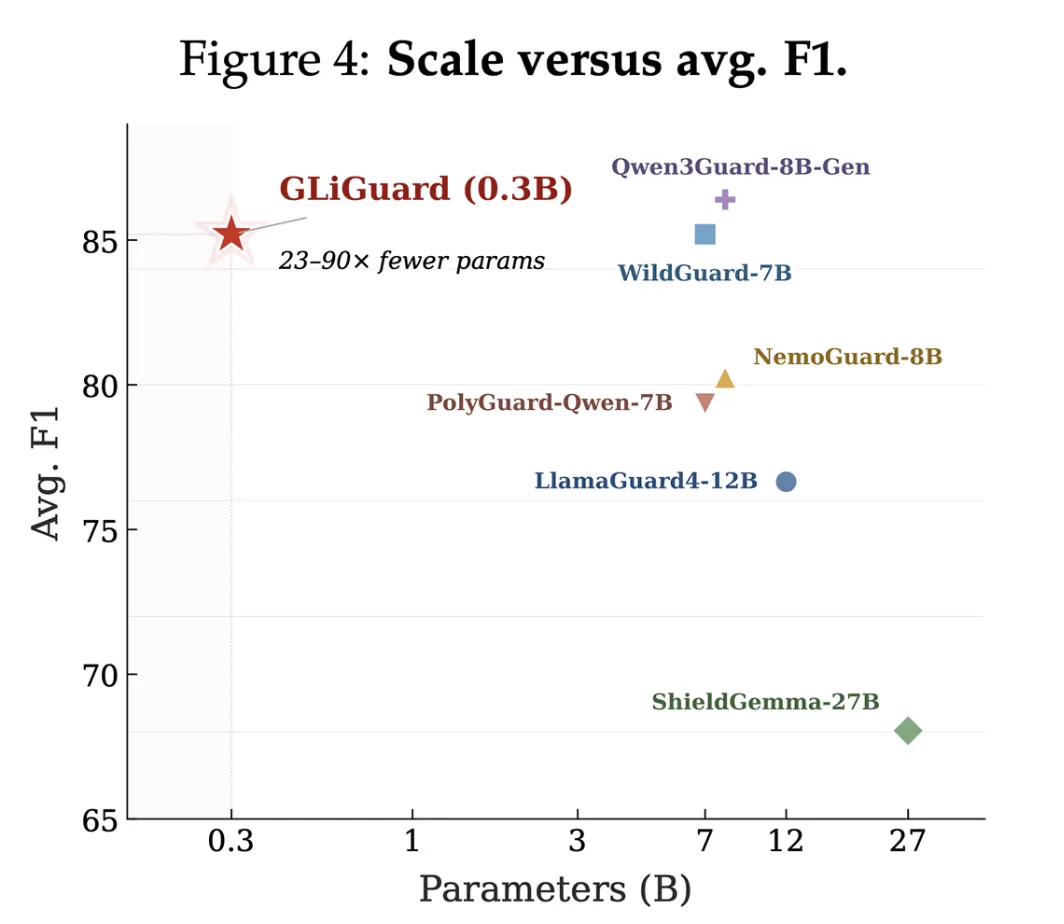
4. Benchmark Dominance Against Massive Models
On nine separate safety benchmarks, GLiGuard matches or exceeds the accuracy of models that are 23 to 90 times its size. For example, it outperforms the 27B ShieldGemma and the 8B NemoGuard on several key metrics, while tying with the 12B LlamaGuard4 on others. This is remarkable because smaller models typically sacrifice accuracy for speed. GLiGuard proves that with the right architecture—encoder-based, designed for classification rather than generation—you do not have to compromise. It achieves high precision and recall across harm categories including toxicity, bias, jailbreak attempts, and unsafe model outputs.

5. Speed and Efficiency That Redefine the Standard
The speed advantage is dramatic. GLiGuard runs up to 16 times faster than comparable guardrail models of similar accuracy. Because it processes all safety dimensions in a single encoder pass, its inference time is not only much lower but also predictable and consistent. This makes it ideal for real-time applications where latency is critical—like AI agents that browse the web, execute code, or interact with external services. Moreover, the small model size means it can be deployed on modest hardware, including edge devices, without sacrificing safety. For developers, this translates directly into lower cloud costs and faster user experiences.
6. What This Means for Production AI Systems
The release of GLiGuard as an open-source model is a game-changer for the AI ecosystem. It offers a viable path to scalable safety moderation without the prohibitive costs of large decoder models. Production systems can now run a lightweight yet highly accurate guardrail on every request, enabling safer deployment of AI agents and LLM-powered applications. Fastino Labs has shown that smaller can be smarter when the task is well-defined. For developers and enterprises alike, GLiGuard represents a practical tool that balances safety, speed, and efficiency—an essential trifecta for the next wave of AI applications.
In summary, GLiGuard proves that safety moderation does not require massive models. By reframing the problem as classification and leveraging an encoder architecture, Fastino Labs has delivered a solution that is both accurate and blazingly fast. Whether you are deploying a chatbot, an AI agent, or any LLM-powered system, this tiny model deserves a spot in your stack.
Related Articles
- Go 1.25 Debuts 'Flight Recorder' for Real-Time Execution Trace Capture
- How Information Theory Revolutionizes Imaging System Design
- Inside the SAP npm Package Attack: Q&A on Developer Tool Supply Chain Risks
- 10 Crucial Updates About Python 3.15.0 Alpha 5
- 10 Critical Truths About JavaScript Date and Time (And How Temporal Will Save You)
- 7 Key Highlights from .NET 11 Preview 4 You Can't Miss
- Stack Overflow's 2008 Launch Shattered Decades of Programming Stagnation, Experts Say
- Microsoft Replaces C++ Node.js Addons with C# and .NET Native AOT in C# Dev Kit