GLiGuard: A 300M Safety Model That Challenges Giants in Speed and Accuracy
Safety moderation is a critical but costly component of production LLM systems. Traditional guardrail models, built on large decoder-only architectures, introduce significant latency and expense because they process each request autoregressively. Fastino Labs has introduced GLiGuard, a compact 300 million-parameter encoder-based model that reframes moderation as a classification task. It matches or exceeds the accuracy of models 23 to 90 times its size while running up to 16 times faster. Below, we answer common questions about this innovative approach.
1. Why is safety moderation so expensive for LLM applications?
In production, every user prompt must be evaluated before reaching the LLM, and every model response must be checked before reaching the user. This means the guardrail model runs on every single request, at every turn of a conversation. With traditional decoder-only models (like LlamaGuard4, WildGuard, ShieldGemma, and NemoGuard), each evaluation generates output autoregressively—one token at a time. This sequential process compounds latency and cost, especially when multiple safety dimensions must be assessed. The larger these models are (often billions of parameters), the more expensive each inference becomes. For high-traffic applications, these guardrail costs can quickly dominate the infrastructure budget.
2. What makes existing guardrail models slow?
Most popular guardrail models are built on decoder-only transformer architectures. They produce safety verdicts autoregressively—token by token—just like a chat model generates a reply. This design was chosen for flexibility: decoder models can understand natural language instructions and adapt to new safety policies without retraining. However, autoregressive generation is inherently sequential, making it slow and computationally heavy. Additionally, each safety dimension (e.g., harm type, prompt injection, unsafe response) is typically evaluated one after another, further multiplying latency. In short, the architecture that provides flexibility is the same one that makes these models inefficient for the classification-heavy task of safety moderation.
3. How is GLiGuard different from traditional guardrail models?
GLiGuard is an encoder-based model that reframes safety moderation as a pure text classification problem, not a generation problem. Encoder models process the entire input in a single forward pass and output a classification label for a set of fixed categories. This eliminates the sequential token generation overhead. As a result, GLiGuard evaluates multiple safety dimensions simultaneously in one pass, dramatically reducing latency. Its compact size (300 million parameters) means it requires far less compute than billion-parameter decoders. While decoder models are general-purpose chat engines, GLiGuard is purpose-built for the specific task of safety classification, making it faster and cheaper without sacrificing accuracy.
4. How does GLiGuard’s performance compare to larger models?
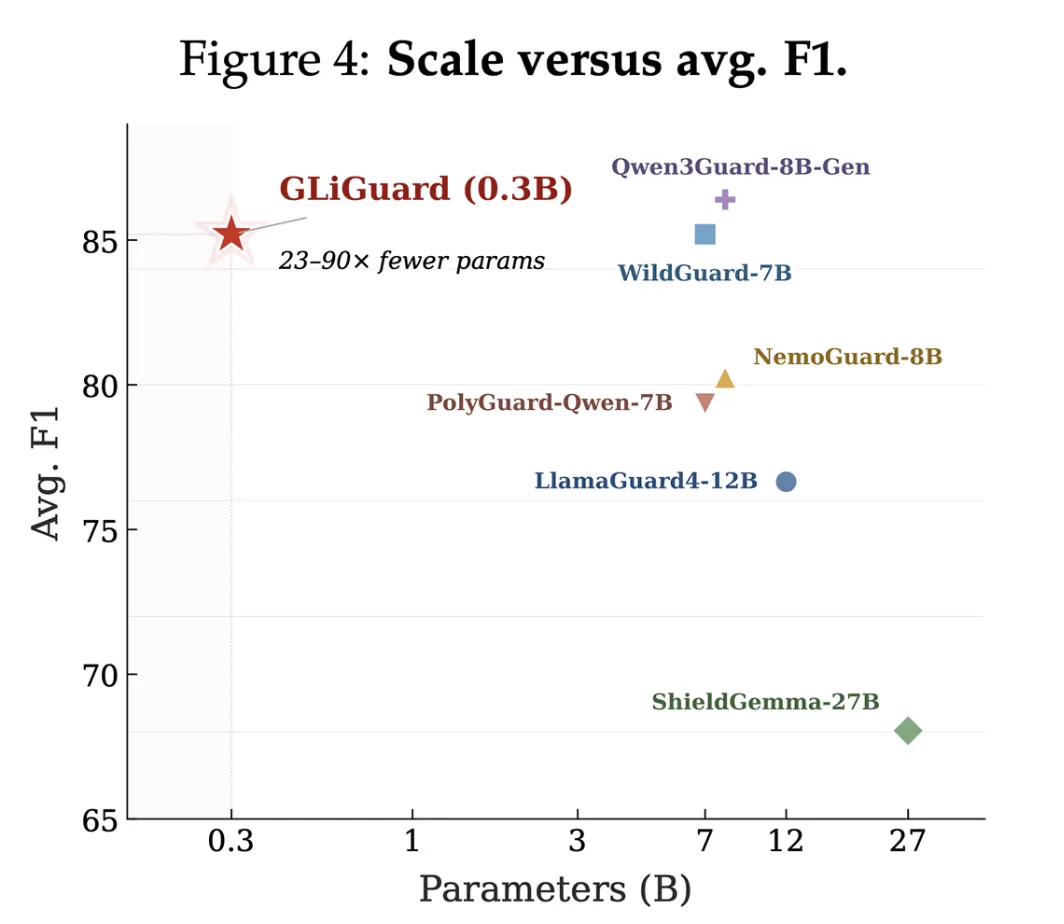
Across nine safety benchmarks, GLiGuard matches or exceeds the accuracy of models that are 23 to 90 times its size, such as LlamaGuard4 (12B), WildGuard (7B), ShieldGemma (27B), and NemoGuard (8B). Despite being just 300 million parameters, it achieves competitive or superior results in detecting harmful content, prompt injections, and unsafe responses. Furthermore, GLiGuard runs up to 16 times faster than these larger models because of its encoder architecture and single-pass classification. This combination of high accuracy and low latency makes it ideal for real-time, high-throughput applications.

5. What benchmarks were used to evaluate GLiGuard?
Fastino Labs tested GLiGuard on nine safety benchmarks covering a broad range of harm categories. These include standard datasets for content moderation, prompt injection detection, and unsafe response classification. The exact benchmarks are detailed in the original blog post at pioneer.ai. Results consistently showed that GLiGuard’s accuracy is on par with or better than much larger models, while its inference speed is dramatically higher. The model performs particularly well in scenarios where low latency is critical, such as real-time chat or agent-based systems.
6. Is GLiGuard open-source and where can I get it?
Yes, GLiGuard is fully open-source and available for use. Fastino Labs released it under an open license to encourage adoption and community improvement. You can find the model weights, code, and usage instructions on their official repository (linked from the blog post). The open-source release allows developers to integrate it into their own safety stacks, fine-tune it for domain-specific policies, or simply use it as a drop-in replacement for slower, larger guardrail models. This transparency also enables independent verification of its claims.
7. Can GLiGuard be customized for domain-specific safety policies?
Because GLiGuard treats moderation as a classification task, it can be adapted to custom safety policies by updating the fixed set of classification labels and fine-tuning on domain-specific data. While decoder models offer flexibility through natural language prompts, GLiGuard’s approach is more structured: you define the harm categories you care about, and the model learns to classify inputs accordingly. For organizations with well-defined safety requirements—such as finance, healthcare, or education—this can actually be an advantage, as it provides consistent, deterministic outputs. The model’s small size also makes retraining and deployment faster than with large decoder models.
Related Articles
- Designing Imaging Systems by Measuring Information Content
- Exploring Python 3.15.0 Alpha 4: New Features and Developer Insights
- New Qt Designer Quiz for Python Developers Highlights Crucial GUI Building Techniques
- Why Bundling Python Apps into Standalone Executables Is So Difficult
- AI-Generated Applications Surge in Enterprises, But Governance Gaps Spark Urgent Concerns
- Inside Python 3.15.0 Alpha 2: Key Features and Release Insights
- Autonomous AI Agents and Cloud Infrastructure: Cloudflare's Bold Move to Give Bots the Keys
- Revolutionizing AI-Assisted Programming: Frameworks, Practices, and Feedback Loops