Kubernetes v1.36: PSI Metrics Reach General Availability – What You Need to Know
With the graduation of Pressure Stall Information (PSI) metrics to general availability in Kubernetes v1.36, operators now have a stable, production-ready tool for detecting resource contention before it escalates into outages. PSI, originally implemented in the Linux kernel in 2018, provides high-fidelity signals that go beyond traditional utilization metrics by measuring the percentage of time tasks spend stalled due to CPU, memory, or I/O pressure. In this Q&A, we explore what PSI metrics are, how they were validated for performance at scale, and what this milestone means for cluster observability.
What Are Pressure Stall Information (PSI) Metrics and Why Are They Important?
Pressure Stall Information, or PSI, is a Linux kernel feature that quantifies resource contention by tracking how long tasks are stalled waiting for CPU, memory, or I/O resources. Unlike simple utilization percentages, PSI captures the real impact of saturation: time lost and tasks delayed. This is crucial because a node might show only 60% CPU utilization while some processes experience severe latency due to scheduling bottlenecks. PSI provides two key data forms: cumulative totals (absolute time stalled) and moving averages for 10s, 60s, and 300s windows. These allow operators to distinguish between transient spikes and sustained pressure, enabling proactive capacity management. Without PSI, teams often rely on noisy, late indicators like out-of-memory kills or application timeouts.
How Does PSI Differ from Traditional Utilization Metrics?
Traditional metrics such as CPU usage percent or memory consumption only show how much of a resource is in use, not whether that usage is causing contention. For example, 80% CPU utilization may be perfectly fine if tasks are running smoothly, or it could hide scheduling delays if high-priority workloads are starved. PSI fills this gap by directly measuring stall time—the percentage of wall time during which at least one task was waiting for a resource. This is analogous to using a speedometer versus a traffic jam indicator: utilization tells you how fast the engine is running; PSI tells you how much time you’re stuck in traffic. The moving averages help operators react to trends instead of noise, making PSI a more actionable signal for resource tuning and autoscaling decisions in Kubernetes clusters.
What Improvements Come with the GA Graduation of PSI in Kubernetes v1.36?
The graduation to general availability in v1.36 means PSI metrics are now a fully stable feature, no longer behind a feature gate. This follows extensive performance validation by SIG Node to ensure minimal overhead. Key improvements include a standardized interface for querying PSI at the node, pod, and container levels via the Kubelet and cgroups. Operators can now rely on these metrics for production alerting and dashboards without worrying about instability or breaking changes. The GA status also signals that the Kubernetes community has rigorously tested PSI under high-density workloads (80+ pods) across various machine types, verifying that collection overhead is negligible—typically within 0.1 cores or 2.5% of node capacity. This makes PSI safe for large-scale deployments.
How Was the Performance and Stability of PSI Metrics Validated?
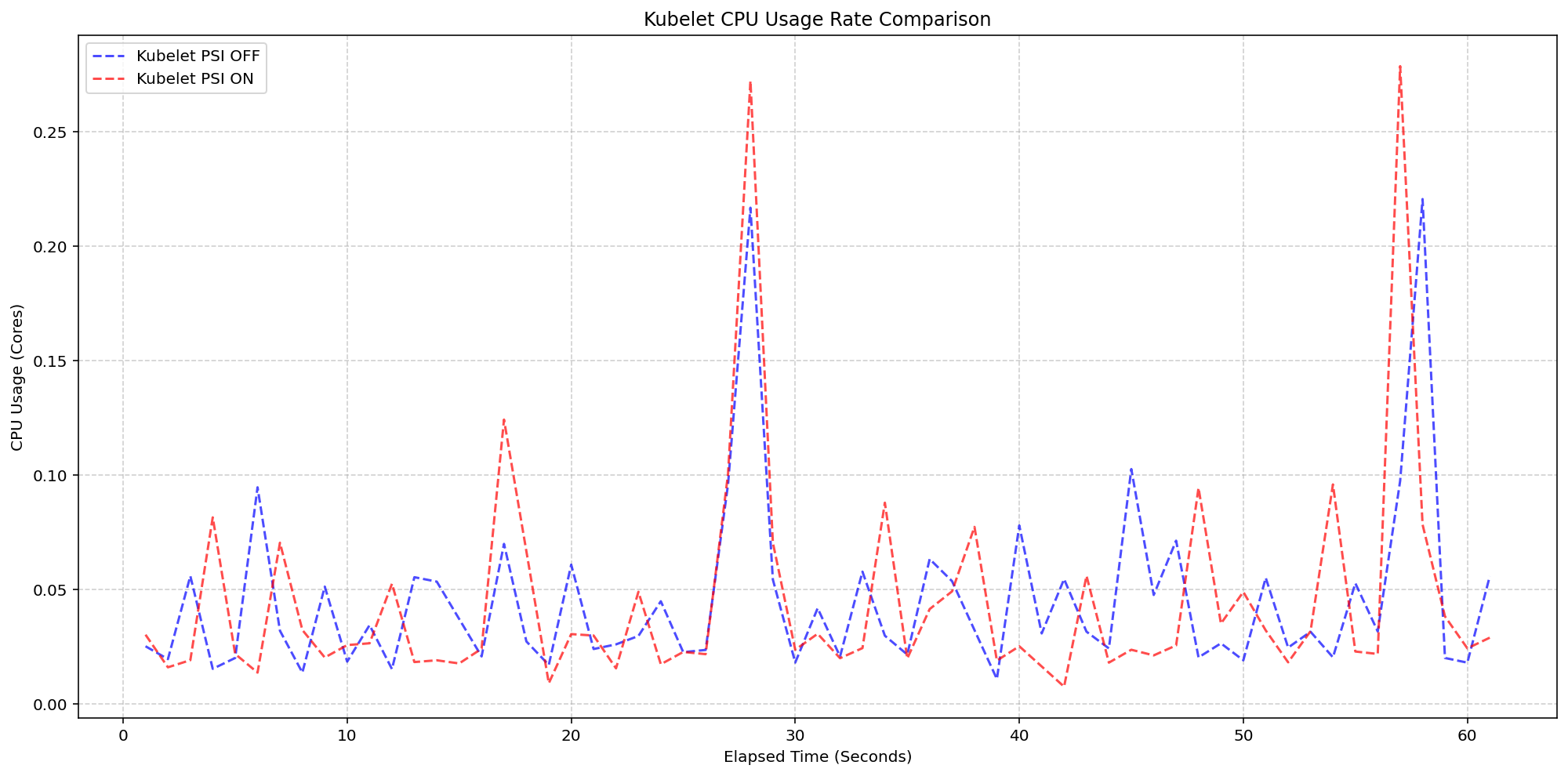
SIG Node conducted controlled experiments on clusters with high-density workloads (80+ pods per node) across different machine types to separate Kubelet overhead from kernel overhead. Two primary scenarios were tested: first, running with kernel PSI enabled but toggling the Kubelet PSI feature gate on or off to measure the Kubelet’s cost of querying and exposing PSI data; second, running with kernel PSI enabled versus disabled while keeping the Kubelet feature on to gauge the kernel’s collection overhead. The tests measured CPU usage rates for both the Kubelet process and overall system CPU. Results showed that the Kubelet’s PSI collection logic is highly lightweight—the CPU usage patterns were nearly identical whether the feature was on or off, staying within 0.1 cores or about 2.5% of total node capacity. Similarly, system-level CPU usage increased only negligibly when the kernel was already tracking PSI (psi=1 by default on many distributions), confirming minimal overhead.
What Were the Results of the Kubelet Overhead Testing for PSI?
For the Kubelet overhead scenario, the team compared clusters with kernel PSI already enabled (psi=1) but with the KubeletPSI feature gate turned off (no active querying) versus on (Kubelet actively reading cgroup pressure files). On 4-core machines, the synchronized CPU usage bursts for the Kubelet were practically identical in both magnitude and frequency, regardless of the feature gate state. This demonstrates that the act of the Kubelet reading and exposing PSI metrics adds no measurable extra load beyond normal housekeeping cycles. The absolute increase was within 0.1 cores—a tiny fraction of total node capacity. This proves that the Kubelet’s PSI collection is safe for production, even on dense clusters. The system-level CPU usage also followed the same pattern between the two cases, with only a slight expected baseline shift due to kernel PSI already running.
What Were the Results of the Kernel Overhead Testing for PSI?
In the kernel overhead scenario, the team measured system CPU usage with kernel PSI enabled (psi=1) versus disabled (psi=0), while keeping the Kubelet feature on. When the Linux kernel is already tracking PSI by default (which is common in modern distributions), enabling the Kubelet to read those cgroup metrics adds only a negligible increase in system CPU usage—approximately 2.5 cores of system CPU on the tested machines, with the Kubelet PSI-enabled cluster following the same pattern as the disabled one. The “slight expected increase from baseline” visualized in the graphs confirms that the overhead comes from the kernel’s monitoring itself, not from Kubernetes reading the data. Since most kernels now ship with psi=1 enabled by default, this overhead is already present; adding Kubelet PSI doesn’t significantly change it. Thus, the feature is safe for production without imposing additional kernel burden.
How Can Operators Use PSI Metrics in Production Environments?
With PSI now GA, operators can integrate these metrics into monitoring stacks—Prometheus, Grafana, custom alert rules—to detect resource pressure before it causes application degradation. For example, setting alerts when the 60-second CPU PSI average exceeds 10% can trigger pod rescheduling or scaling actions. PSI also helps diagnose noisy neighbors: a container with high memory pressure can be identified by its stall percentage. Additionally, PSI complements traditional metrics for capacity planning: sustained memory pressure over 300-second windows might indicate the need for larger nodes or memory limits adjustments. The Kubelet exposes PSI data through the /metrics/resource endpoint, making it accessible via standard Kubernetes metrics pipelines. Operators should also note that PSI is available per cgroup, enabling per-container granularity—perfect for fine-tuning resource requests and limits based on real contention, not just usage.
Related Articles
- Linux Mint Launches Urgent HWE ISOs to Fix Hardware Support Gaps
- Meta Unveils KernelEvolve: AI Agent Automates Chip Optimization, Boosts Model Performance by 60%
- How Meta's AI-Powered Agents Supercharge Hyperscale Efficiency
- ARCTIC Fan Controller Driver Set to Debut in Linux Kernel 7.2
- 6 Key Highlights of the Framework Laptop 13 Pro's Ubuntu Certification
- Fedora Linux 44: What’s New and How to Get It
- Testing Sealed Bootable Container Images for Fedora Atomic Desktops
- AI-Powered Code Review Unearths Long-Standing Bugs in Linux's sched_ext Scheduler